-
컴퓨터 네트워크 7주차: Handshake, Flow Control, Congestion Control교내 강의/컴퓨터 네트워크 2024. 4. 19. 14:55
Flow Control:
sender는 receiver를 놀래키면 안된다.
buffer overflow가 생기지 않도록 보장함.
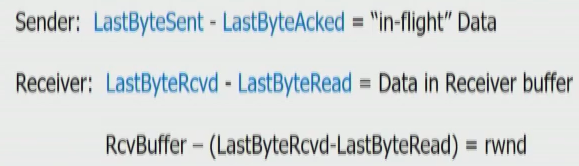
receiver는 TCP 헤더에 free buffer space를 rwnd로 넣어서 보냄.
In-flight(unacked) Data <= rwnd.
LastByteSent - LastByteAcked <= rwnd.
rwnd = RcvBuffer - (LastByteRcvd - LastByteRead)
= RcvBuffer - (수신했지만 상위 계층으로 전송하지 않은 데이터들)
Connection Management(hand shake):
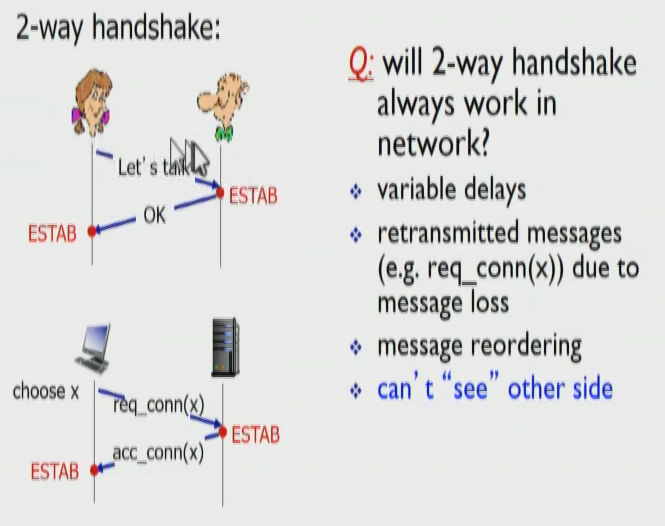
2 way의 문제점:
receiver는 sender가 제대로 듣고 있는지 알 수 없음.
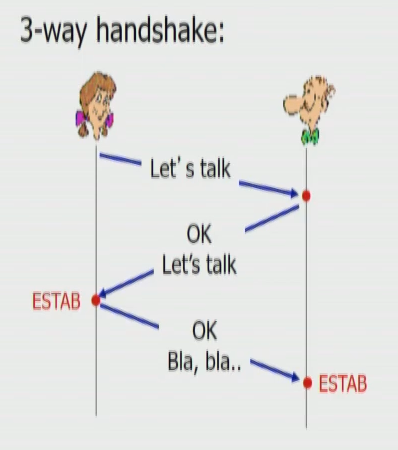
3way시 client는 ack와 함께 content를 보내면 됨.


1. Client: syn CISN(Client Initial Sequence Number: Random)
2. Server: syn ack(CISN+1) SISN(Server Initial Sequence Number: Random)
3. ack(SISN+1) +data

두 호스트 간의 연결을 끊을 때에도 handshaking이 필요하다.
만약 송신자 측에서 "나는 보낼 거 다 보냈음" 하고 연결을 끊어버리면, 수신자가 아직 보낼 데이터가 남아 있을 수도 있는데 일방적으로 끊는 셈이 된다. 반대도 마찬가지.
즉, 상호 간에 "나는 너한테 보낼 데이터 다 보냈고 더이상 보낼 것은 없다" 라고 확인이 되어야 연결을 끊을 수 있다.
따라서 송/수신자 간에 연결을 끊자는 뜻의 FIN 과 거기의 응답인 ACK가 두 번 오간다.
마찬가지로 두 호스트는 각각의 메시지 교환 시점에 따라 상태가 바뀌게 된다.
마지막 ack는 timed wait for 2*max segment lifetime으로 충분하게 잡는다(약 30초)

Server:
Closed에서 Listen상태로 됨=>syn을 받을 수 있게 포트를 오픈함.
Syn이 오면 Synack를 보내고 메모리를 할당을 대기함(바로 할당 시 DoS에 취약)
Synack에 Hash기법을 통해 secretNo을 포함시킴.
ack가 오면 nothing -> Establised됨.
Congestion Control:
Flow control은 end-to-end
Congestion Control은 라우터 범위.

Scenario 1) 라우터 버퍼가 무한한 경우:
람다in이 특정 수치를 넘어서면 람다out은 수렴하고 딜레이는 끝 없이 늘어남. (bottle neck)
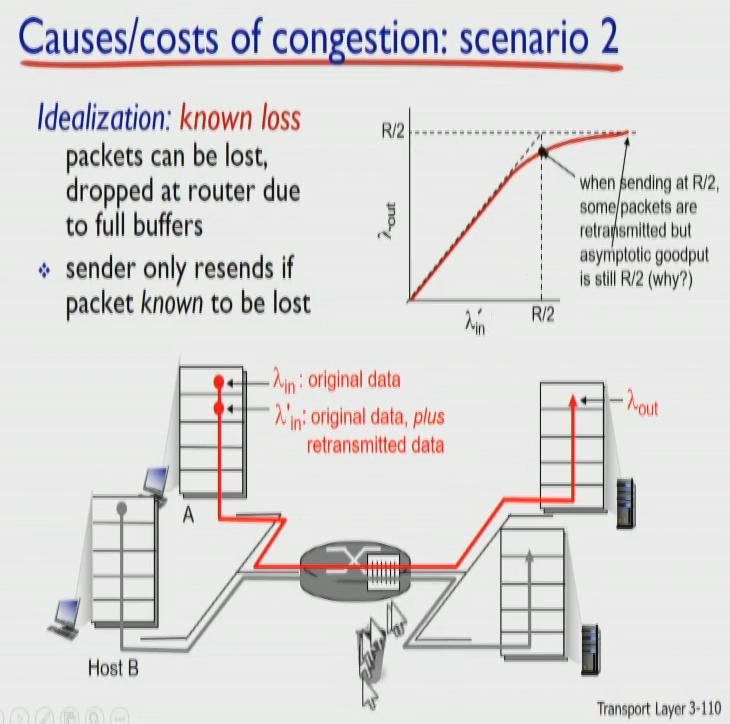
Scenario 2) 라우터 버퍼가 유한:
람다in은 패킷copy를 보냄 (client는 드랍의 유무를 알 수 있음)
드랍된 경우 재전송, 아닌경우 원본 삭제.
그래프에 생긴 람다out의 차이는 드랍으로 인해 발생. (duplicate된 패킷은 람다out에 영향을 안주기 때문.)
ABR(Available Bit Rate):

탄력적 서비스:
TCP Congestion Control:
~~~~다시 작성,...

MSS(maximum segment size, window size)를 점진적으로 증가, (1RTT마다 1MSS씩 증가시킴)
congestion(loss)이 발생하면 window size를 절반으로 줄인다. (그래프 확인)
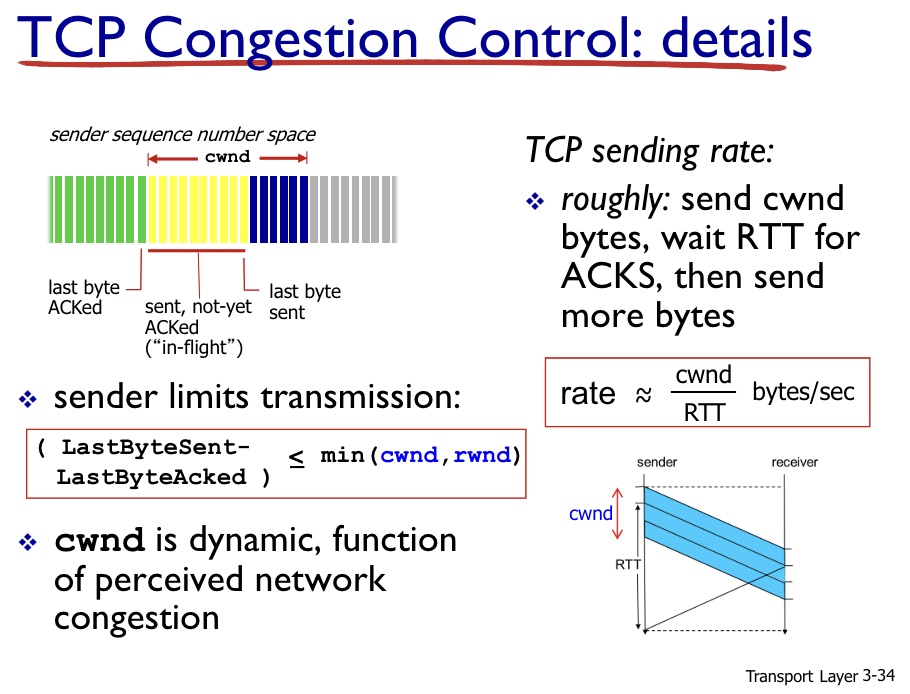
기존 Flow Control에 cwnd를 넣음
cwnd는 rwnd보다 작고 dynamic하게 변함.
cwnd를 RTT로 나누면 대략적인 Rate을 알 수 있음


이대로 2배씩 계속 전송 속도를 높이면 Congestion이 생길 것이고 time-out이 이 loss를 detect할 것이다.
Detect 이후 TCP Tahoe, RENO:
cwnd를 1로 줄임. 1부터 다시 threshold까지 2배씩 증가, 이후 선형증가.
loss가 3 duplicate Acks로 detect:
cwnd를 1/2로 줄임 -> 선형증가.

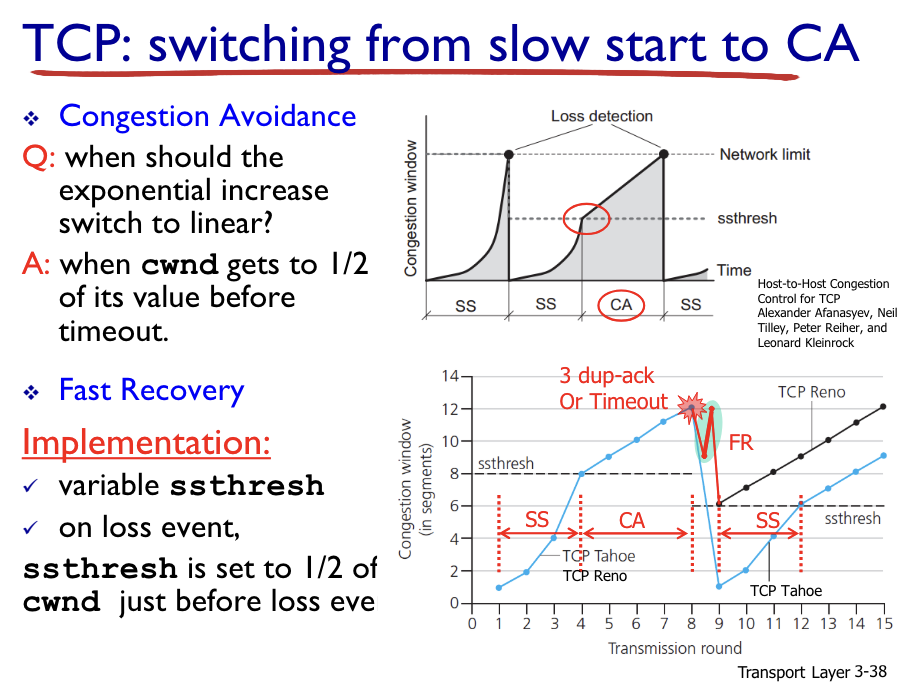
Tcp Congestion Control은 3가지 방식:
Slow Start: cwnd 1부터 시작, 2배씩 증가
Congestion Avoidence: 2배증가에서 선형증가로 언제바뀜? => 이전 timeout 값의 1/2.
Fast Recovery: 3 duplicate ack 발생 시 loss패킷을 다시 보내고 cwnd를 1/2값으로 세팅.
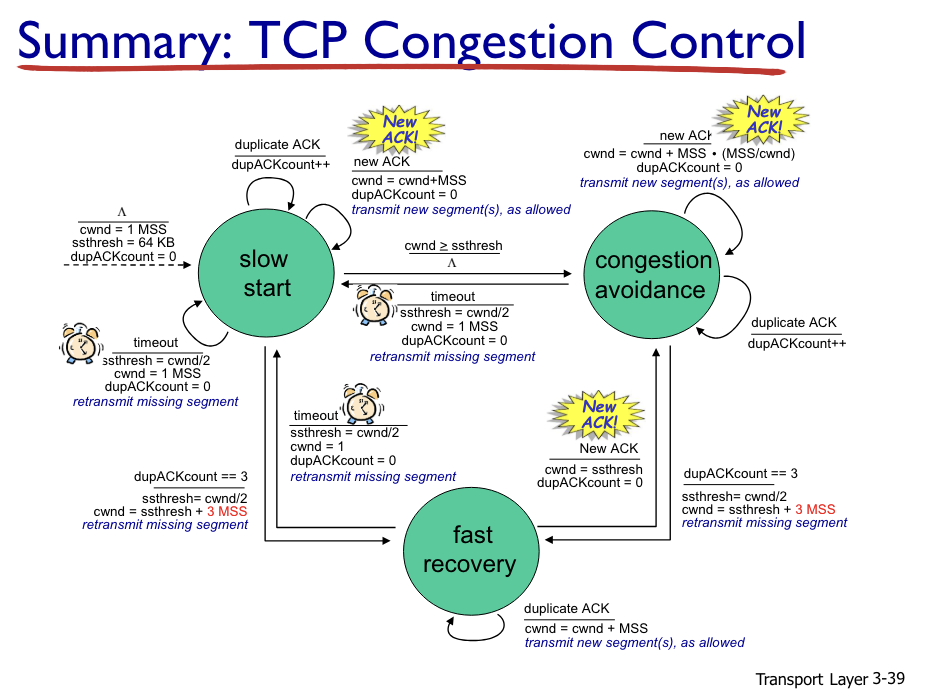
TCP Fairness:
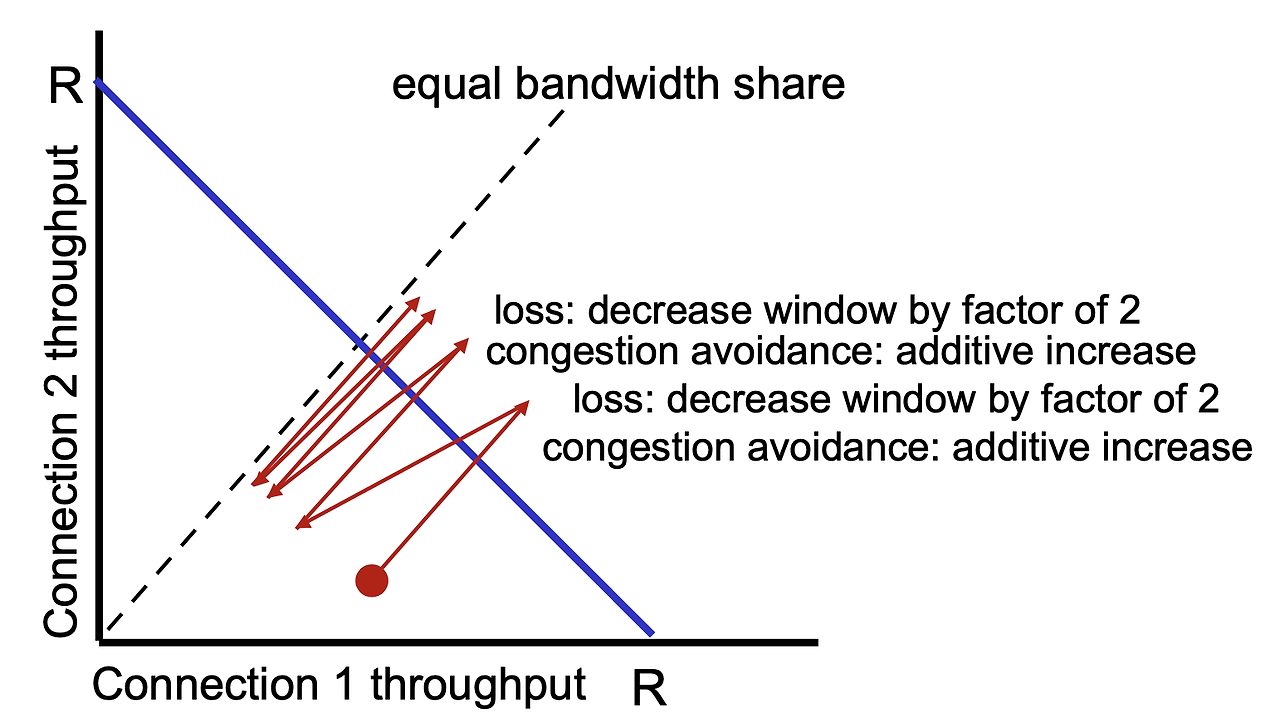
Congestion Control과정에서 cwnd를 반씩 줄이는 것이 반복되다 보면 라우터를 사용하는 채널들의 cwnd가 정규화 됨.
UDP
TCP는 혼잡 제어를 지원하기 때문에 위와 같이 cwnd를 늘리고 줄이고 하는 과정을 자기네들끼리 거친다. 그런데 UDP는 그러한 기능이 없다. 즉 UDP는 TCP들끼리 혼잡 제어를 하든 말든 슉슉 지나갈 수 있다. 이러면 공평성이 깨지게 된다.
Multi-TCP
TCP connection끼리 대역폭을 나눌 때, connection의 개수로 /k 하여 일정하게 나눈다. 그러면 한 프로세스가 편법으로 여러 개의 TCP connection을 열면, 그만큼 더 많은 대역폭을 할당받을 수 있다. 만약 10개의 프로세스가 1개씩을 열었는데, 새로 들어온 프로세스가 1개를 열면 1/11을 할당 받겠지만, 10개를 열어버리면 10/20으로 1/2나 차지할 수 있다.
'교내 강의 > 컴퓨터 네트워크' 카테고리의 다른 글
네트워크 9주차: Net) IPv4, CIDR (1) 2024.05.15 컴퓨터 네트워크 9주차: Net) VC, Router (0) 2024.04.30 네트워크 6주차: TL (TCP: Window, Timeout) (0) 2024.04.13 네트워크 6주차: TL (rdt 3.0, Packet pipelining (GBN, SR)) (0) 2024.04.12 네트워크 5주차: Transport Layer (Multiplexing, Demultiplexing, PDU, RDT) (1) 2024.04.03